Self-Healing Tests Need an Operator, Not a Vibe
AI-assisted test repair can reduce maintenance toil, but only if teams define what may heal automatically, what requires review, and what evidence proves the test is still protecting the behavior users depend on.

Self-Healing Tests Need an Operator, Not a Vibe — 60-second summary
The most seductive promise in QA automation is not that AI will write every test for you. It is that the tests you already have will stop breaking every time the product changes.
Anyone who has maintained a browser test suite knows the pain. A button gets renamed. A component moves. A generated class changes. A flow still works for users, but the test cannot find the element anymore. The build goes red, the team loses an afternoon, and the fix is not product engineering. It is test plumbing.
That is the reasonable case for self-healing tests. Modern tools increasingly claim they can adapt to UI drift, repair locators, regenerate steps, or suggest updates when the application changes. Self-healing test tools can reduce locator-maintenance work, but the useful question is whether the repair leaves evidence a human can review. Testim says its Smart Locators analyze many element attributes, learn across runs, and can improve degraded locators. Some self-healing testing products also position debugging views and captured element context as part of the repair loop, but the package should avoid depending on any vendor-specific claim unless that vendor's current docs are reachable during final QA. Playwright's generator can record flows, generate locators, and add assertions that humans can inspect and improve.
That is useful. It is also dangerous if teams treat it as magic.
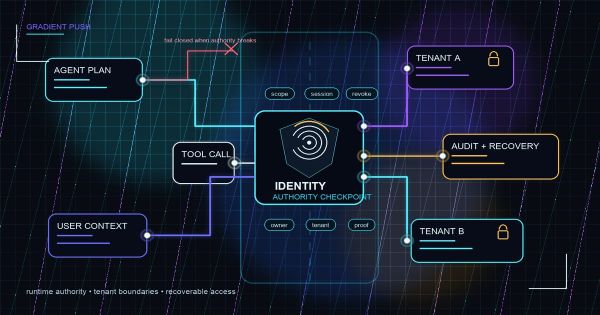
The product docs themselves point to a more sober model. High-risk flows should fail closed when a repair is uncertain; a quiet green test is not proof the product behavior is still right. Testim says auto-improved locators create a revision and surface changed steps. Other vendor materials commonly acknowledge the same underlying risk: a healed test can still pass for the wrong reason if the team does not review what changed. These are not vibes. They are governance controls.
A test that heals itself is not just recovering from brittleness. It is changing the evidence your team uses to decide whether the product still works. That means the central question is not, "Can this tool repair the test?" It is, "Who decided this kind of repair is safe, and where is that decision recorded?"
The difference between maintenance and meaning
Some test failures are maintenance failures. The checkout button is still the checkout button, but its selector changed from #checkout to a component-generated value. A low-risk test repair that finds the same visible button and preserves the same assertion can save real time. That is exactly where self-healing belongs: locator drift, repetitive UI maintenance, flaky-but-low-risk interactions, and generated regression coverage around stable flows.
But other failures are meaning failures. A permissions regression lets a user see an admin-only page. A checkout flow skips tax calculation. A data-deletion workflow changes copy, confirmation behavior, or authorization scope. In those cases, the test breaking may be the signal. If an over-eager healing system rewrites the test to match the broken behavior, the team does not get resilience. It gets a green build with less truth in it.
That is the false-confidence trap. The automation can make the suite quieter while making the product less governed.
The line is not always obvious because UI tests combine two things that should be controlled separately: how to find the thing, and what the thing must prove. A locator is implementation plumbing. An assertion is a product claim. Healing the first may be safe. Healing the second without review is usually a governance mistake.
Locator repair and product assertions are different controls. A healed locator still needs assertions that prove the right business outcome happened. That is the lesson teams should generalize. Self-healing needs a boundary around what the system is allowed to reinterpret.
Where self-healing helps
The strongest use case is boring, frequent, and local.
A component library update changes element attributes but not the behavior. A marketing tweak changes a button label but the flow remains the same. A test recorder generated a brittle locator and the tool can replace it with a more stable locator. A low-risk regression test has been failing because the UI moved, not because the product broke.
In those cases, automatic or one-click repair can reduce toil. It can keep teams from ignoring red builds. It can let QA and engineering spend more time on coverage, exploratory testing, and failure analysis instead of selector babysitting.
It can also help with test generation, as long as the team remembers what generated tests are good at. Tools can record happy paths and produce useful scaffolding. Playwright's generator, for example, can record actions and generate basic assertions, with an explicit expectation that the resulting file can be inspected and improved. That is the right mental model: generated tests are drafts of evidence, not evidence by default.
The same applies to self-healing. It should make the maintenance layer cheaper. It should not silently redefine what passing means.
Before you trust a self-healing repair, decide which workflows are allowed to heal quietly and which ones must fail closed for review.
Check your self-healing test boundary
Where it should fail closed
Some surfaces should not auto-heal without review:
- Payment, billing, refund, and checkout flows.
- Authentication, authorization, tenancy, and permission boundaries.
- Data deletion, export, retention, and privacy-sensitive workflows.
- Compliance-sensitive flows where audit evidence matters.
- Any assertion tied to business-critical behavior, not just UI presence.
- Any repeated heal on the same flow, because repeated healing may signal product instability rather than test stability.
The operating rule is simple: if the test protects a promise users or the business depend on, the system should not be allowed to rewrite that promise on its own.
That does not mean AI assistance is banned on high-risk flows. It means assistance changes mode. The system can propose a repair, collect screenshots, compare before/after element histories, show a locator confidence score, or generate a patch. But a human owner should approve the change before the suite treats the new behavior as green.
This is consistent with the broader direction of software testing practice: tests are not just scripts, they are managed evidence about product risk. The important lesson for self-healing is not that every startup needs a standards ceremony. It is that tests are supposed to be governed as risk controls. The more risk a test covers, the less comfortable the team should be with silent mutation.
The operator model
Self-healing tests need an operator model: a small set of rules that define what the tool may change, what evidence it must keep, and who owns the review boundary.
Start by classifying test surfaces.
Low-risk maintenance tests can auto-heal locator drift when the behavior assertion remains intact. Medium-risk flows can allow suggested heals, but require review when assertions, workflow order, or target elements change materially. High-risk flows should fail closed by default and require explicit approval for any repair that changes what the test proves.
Then separate locator changes from assertion changes.
A locator update says, "This is still the same thing." An assertion update says, "This behavior is now acceptable." Those are different decisions. The first can sometimes be automated. The second should usually be reviewed.
Keep evidence.
Every heal should leave a trail: old locator, new locator, screenshot or DOM evidence, confidence score or match explanation if the tool provides one, test owner, approval status, and link to the run where the heal occurred. If the tool marks self-heals visually, creates a revision, exposes element history, or provides before/after views, make those review artifacts, not debugging trivia.
Monitor heal frequency.
A test that heals once after a planned UI refactor is probably healthy. A test that heals repeatedly around the same flow is a smoke alarm. It may point to unstable UI, weak selectors, ambiguous product behavior, or a suite that is learning around defects.
Finally, define rollback.
If a heal is later found to be wrong, the team should know how to revert the test, re-run the prior expectation, and inspect which releases were certified under the bad evidence. Without that rollback path, self-healing becomes a memory hole.
Check your self-healing test boundary
Before a self-healing repair is allowed to keep a test green, decide whether the workflow is safe to repair automatically or must fail closed for review.
| If the repaired test touches... | Default route | Evidence to keep |
|---|---|---|
| Cosmetic UI drift with no customer, money, permission, deletion, or compliance impact | Allow auto-repair if the assertion still proves the intended outcome | Changed element, before/after screenshot, passing assertion, reviewer note if confidence is low |
| Identity, permissions, role changes, or account access | Fail closed for review | Repaired selector, affected role/account path, reviewer approval, linked ticket or run note |
| Money movement, billing, ordering, refund, deletion, compliance, or customer-impacting state | Fail closed for review | Business object affected, assertion result, reviewer approval, rollback/retry decision |
| Uncertain locator match or missing assertion evidence | Fail closed until the assertion is repaired | What changed, why the tool matched it, which assertion now proves the right outcome |
A healed locator is maintenance evidence, not product evidence. Let low-risk UI drift repair itself; make customer-impacting workflows prove the repair before the test stays green.
Before enabling self-healing broadly, answer these questions:
- Which tests are allowed to auto-heal without review?
- Which flows must fail closed?
- Can the tool distinguish locator repair from assertion or workflow change?
- What evidence is stored for every heal?
- Who reviews medium- and high-risk repairs?
- What heal frequency triggers investigation?
- Can the team roll back a bad heal and identify affected runs?
- What does a green build mean after a heal occurred?
Use this as the self-healing test boundary check: if the flow carries money, identity, permissions, deletion, compliance, or customer-impacting state, the system may suggest a repair, but it should not silently redefine the passing condition.
The last question is the most important. A green build should not mean, "The tool found a way to keep going." It should mean, "The product still satisfies the behavior this test was created to protect."
Self-healing tests are not a bad idea. They are a powerful maintenance layer for a class of failures that has wasted engineering time for years. But the more autonomous the test system becomes, the more explicit the operating boundary needs to be.
If a system can change the test, it also needs evidence, ownership, and a review boundary. Otherwise, it is not healing your test suite. It is teaching your release process to trust less evidence with more confidence.
If a repaired test touches money, identity, permissions, deletion, compliance, or customer-impacting state, the repair should produce evidence before the run stays green.