Persistent Agents Need an Ops Layer
Why long-running agents turn memory design into an ops problem, and what teams should govern before background workflows become invisible operational risk.
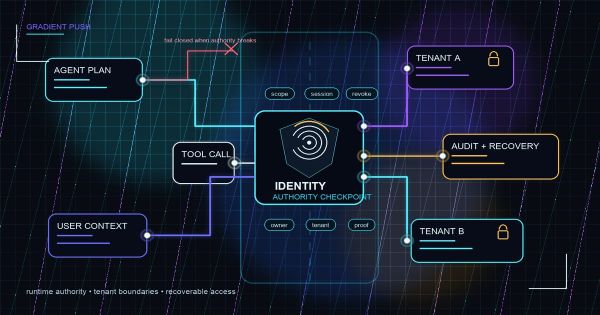
Persistent agents are not just chat with better memory. Once they keep state, resume work later, and act across background jobs, they start behaving like operational systems that need checkpointing, recovery, observability, and human control.
A lot of teams still talk about persistent agents like they are a memory upgrade.
That framing misses the real shift.
The moment an agent can keep context across sessions, resume work after a pause, survive interruptions, or keep running in the background, you are no longer shipping a better chat interface. You are operating a stateful system that can fail between interactions.
At that point, the product question becomes an operations question.
The hard problems are no longer just prompt quality, model choice, or tool access. They are checkpointing, recovery, stale state, retry policy, expired auth, human review, and whether anyone can tell what the agent is doing once it leaves the foreground.
That is the category change teams underestimate. Persistence does not just make an agent more useful. It widens the failure surface and creates an operator burden most product teams have not staffed for.
The cleanest way to say it is this: persistent agents should be governed more like workflows than chats.
If you only do one thing this quarter, do this: pick one persistent workflow and map its full lifecycle. Write down where conversation history lives, where live task state lives, what gets stored as long-term memory, what happens when the run pauses, how it resumes, who owns recovery, and how a human interrupts it safely. That exercise will tell you very quickly whether your persistent agent is a product feature or an operational liability.
Why persistence changes the architecture
Persistence sounds simple when you see it in a demo.
The agent remembers the thread. It resumes a task later. It picks up where it left off.
But under the hood, that means your system now has to preserve state across time, failures, and human interruption. It needs to know what belongs to the current conversation, what belongs to the current task, what should persist across many sessions, and what should never be carried forward at all.
That is not just memory design. It is systems design.
The official platform docs are increasingly explicit about this. OpenAI's background mode treats long-running work as asynchronous and expects developers to track request state until it reaches a terminal status. LangGraph frames durable execution around checkpoints, threads, and replay after interruption. Google's ADK separates session, state, and memory into different layers of conversational context. Across all three, the pattern is the same: persistence may show up as a product feature, but reliable persistence depends on operating discipline.
Stop treating all persistence like one bucket
One reason teams get this wrong is that they collapse several different problems into the word "memory."
That shortcut makes the architecture worse.
Conversation history is not the same as live task state. Live task state is not the same as long-term memory. Durable execution history is not the same as user profile memory. If you store all of those in one fuzzy layer, you get agents that drag stale context into new work, resume from the wrong point, or quietly depend on state nobody can inspect cleanly.
A better split looks like this:
- Conversation history: what was said and done in the current thread.
- Task state: what the agent is actively working on right now, including progress, pending steps, and intermediate artifacts.
- Long-term memory: reusable information worth carrying across sessions.
- Execution history: checkpoints or replay state that let the system recover after interruption.
Operators do not need those layers to sound elegant. They need them to fail differently. If they blur together, teams cannot tell whether the agent forgot, resumed incorrectly, pulled stale user context, or replayed a workflow from the wrong checkpoint.
The real failure surface shows up after the demo
This is where the ops layer becomes unavoidable.
Persistent agents do not just fail by giving a bad answer. They fail by getting stuck, replaying the wrong action, quietly carrying stale assumptions forward, or completing work nobody can confidently audit.
A background run can stall in a queued or in-progress state with no clear owner. A checkpoint can restore the workflow, but it can also replay the wrong side effect if the system was not designed for deterministic recovery. An auth token can expire halfway through a long-running task. A human approval step can sit unresolved while the agent's state quietly goes stale. A resumed task can keep moving on assumptions that stopped being true while the workflow was paused.
Those are not exotic edge cases. They are the operating reality of any system that stretches work across time.
That is why the right question is not "does the agent have memory?" It is "what happens when this workflow gets interrupted, delayed, retried, or manually overridden, and who can see, control, and clean up that state when it does?"
What builders should govern first
Start with visibility.
If an agent can work in the background, you need to know whether it is queued, running, blocked on auth, waiting on human input, failed, or resumed after interruption. Invisible background work is where trust breaks first.
Then define ownership.
Who is allowed to retry a stuck job? Who can cancel it? Who approves a resume after auth is refreshed? Who reviews the output if the task ran for an hour and touched customer data or production systems? Who gets paged when the workflow is still live but nobody is clearly responsible for the next move? Persistence without ownership is just automation nobody actually owns.
Next, design for recovery, not just completion.
LangGraph's durability guidance is useful here because it makes the recovery constraints explicit: resumable systems need deterministic replay, careful handling of side effects, and deliberate durability tradeoffs. That is the mindset persistent agents need. Recovery is not a bonus feature. It is part of the product.
Finally, make manual interruption a first-class path.
If a user, operator, or reviewer cannot stop, inspect, and safely resume a persistent workflow, you do not have a production-ready agent. You have a background job wearing an agent label.
What an ops layer must provide
At minimum, a production-worthy persistent agent needs six operating guarantees.
- State separation: conversation history, task state, long-term memory, and execution history must be distinguishable.
- Observability: operators need live status, failure state, and resume context rather than a black box.
- Recovery discipline: retries, replays, and checkpoints must not duplicate unsafe side effects.
- Human control: an authorized person must be able to inspect, pause, cancel, and resume safely.
- Audit trail: the system should show what happened, what state changed, and why a run was resumed, retried, or overridden.
- Accountability: one owner must exist for overrides, cleanup, and post-failure decisions.
If those guarantees are missing, the system may still look impressive in a demo, but it is not ready to be trusted as production infrastructure.
This is the standard teams should use to decide whether a persistent agent is really a product capability or just an operational liability with a good interface.
What to do this quarter
Run one persistence review on a live workflow.
Keep it simple:
- Identify where conversation history, task state, long-term memory, and execution checkpoints are stored.
- Mark which state is thread-scoped, user-scoped, app-scoped, or temporary.
- Define terminal states, stuck states, and who owns recovery for each.
- Test what happens when auth expires, a human review pauses the run, or a background job resumes late.
- Add one operator view that makes the workflow observable, auditable, and manually interruptible.
Most teams do not need a giant memory strategy deck first. They need one honest map of how state moves, stalls, and recovers in a real agent workflow.
That is the point where persistent agents stop being a demo trick and start becoming governable infrastructure. It is also where teams stop confusing memory features with production readiness.
Operator Checklist
Before you trust a persistent agent in production, make sure you can answer yes to these:
- Can you distinguish conversation history from live task state, long-term memory, and execution history?
- Can you see whether a background run is queued, active, waiting on auth, waiting on human review, failed, canceled, or done?
- Can you recover from an interrupted run without replaying unsafe side effects?
- Can you tell when auth expired, state went stale, or ownership became ambiguous?
- Can a human inspect, cancel, override, or resume the workflow safely?
- Can you reconstruct what happened from status, checkpoint, and override history?
- Does one owner actually exist for retries, overrides, and post-failure cleanup?
If the answer is no on several of those, the next improvement is not a better prompt or a bigger memory store. It is an ops layer.
Builder Tip
Persistent agents should be operated more like workflows than chats. If work can pause and resume, your system needs checkpoint rules, recovery paths, and human controls that match that reality.